您可以同时关注中科曙光微信公众号
使用微信扫一扫即可登录! 查阅资料更方便、 快捷!

2025年1月
服务热线:400-810-0466

Introduction
Unlike the database system in general information service industry, scalability is the most important indicator for designing database in network monitoring system. Data increase scale of the ordinary data center may grow soon, but Internet data has an explosive growth. Although many current Internet monitoring systems adapt to the size of the storage system by means of simplifying data, but this is not the way to solve the problem. In Internet industry, there is an argument that "problems that can be solved by money (purchase of equipment) shall not be regarded as problems, but the problem is that even money won't solve the problem", which can be indicated by storage of database for mass data.
Currently, mainstream of data used in domestic Internet monitoring industry is Oracle; when a single Oracle performance reaches bottleneck, Oracle RAC becomes popular, but as is shown, successful cases for actual use of Oracle RAC have generally only 4 nodes, and it is very unsafe to scale up, because RAC is generally used in application of OLTP online transaction, and its applied characteristic is that there are a large number of concurrent users, but the amount of data for individual queries is small with short time. Application scenario of network monitoring system is facing high concurrent loading data with mass storage and low concurrent queries, but the size of each query is very high. Therefore, traditional database system is difficult to support database storage service of large network monitoring system. In the process of long-term service for Internet monitoring industry, Sugon sums up the characteristics of Internet monitoring industry database storage, and develops the database system DRAC specially in view characteristics of network monitoring database through cooperation with intelligence center of the computing institute, which has been successfully deployed in large projects of multiple countries. Its underlying uses shared -nothing nodes of oracle data as data nodes, which has good scalability and system reliability. DRAC software transparently translates users’ operating into the operation of the underlying database, presented to users as a single database system. DRAC system can implement multilevel storage solution according to the data's access frequency and importance, so as to reduce cost of the whole system and improve system performance.
Technical characteristics
Sugon cluster parallel database DRAC (Dawning's Real Application Cluster) is a parallel database management system with a shared-nothing structure. DRAC is a parallel database system specially designed for analysis of network monitoring data, which has been deployed in a large national project and a municipal large-scale project and many other systems. It has the following characteristics:
DRAC adopts mainstream cluster design method at present, which has high cost performance, good extensibility and many other advantages.
It directly resolve any queries into subquery that is operated on partition data and post-processing query for summarizing the intermediate results, and the mature DBMS is used to implement two kinds of queries, so as to avoid complexity introduced by the average distributed query processor for general introduction. Fit for partition strategy for a particular application, DRAC method can guarantee the efficiency of query.
Parallel processing of large tasks. DRAC adopts the stand-alone database as the basic data processing unit to write the data into these unit databases in parallel, and read and process these data from each database during query in parallel. This fully parallel processing has greatly enhanced the system's ability to store data and shorten the time of individual query. DDL operation has also been implemented on the database node in parallel execution.
DRAC provides a single system image, and users make use of interface similar to ODBC or JDBC to submit SQL statements. These actions are automatically executed in parallel by the service nodes.
DRAC adopts a design idea of function separation; loading and query function can be configured according to needs to meet high availability requirements for online extension.
Different from Oracle RAC and other parallel databases, DRAC does not need fiber switches and higher-end disk array, and the hardware cost is low. With flexible deployment and tools for simplifying management, DRAC has a higher cost performance in large-scale deployment.
System architecture
The figure below shows a typical DRAC configuration. Nodes in the system are divided into two categories: database nodes of data storage and service node providing parallel data management functions. The latter includes service loading, service query, data replication and data definition services. All types of nodes can be flexibly configured according to the needs of capacity and performance.
Database node is a commercialized server with separate storage system (local hard disk or disk array). Nodes are installed with stand-alone version of Oracle database management system. In accordance with data partitioning strategy, each database node saves all the replicated data and a part of slice data table. Data on each database node can use Oracle's index, partitions and other characteristics.
The function of a database is divided into loading, query, data replication, data definition and other services; each service is deployed on a single physical node. Any service node is set up to all database connections. Loading nodes start several loading thread, which will write a batch of data into a database node. Owing to mass data distributed and stored in each database node, query service will first obtain the intermediate results in parallel through treatment of various data in local database node, and then sum up the intermediate results together into the final results. Data replication refers to storing a table of data to a set of database nodes at the same time, in order to avoid joint operations of two tables. Data replication service is dedicated to processing operation of this part. It operates business through the distributed transaction in the related nodes at the same time, so as to guarantee the replicated data is consistent. Data defining services is used to maintain metadata of the system; it executes table structure in parallel, table space and other database schema change and other metadata operations.
Using design of this service separation, users can flexibly configure the number of a variety of services, in order to achieve the best utilization of system resources.
Shared-nothing architecture
DRAC takes shared-Nothing architecture, that is, except Internet for all database nodes of all storage data nodes, no resources will be shared. In addition, parallel database is divided into Shared - Memory and Shared - Disk architecture. Academic circles generally believed that Shared-Nothing architecture has a strong extensibility. In addition, DRAC doesn't need to store network facilities, and also does not rely on expensive high-end disk array, which can well reduce the hardware cost with high cost performance in large-scale deployment.
Shared - Memory structure is connected with more shared memories through memory bus by many processors, and then share multiple storage devices again through I/O bus sharing. Shared - Memory structure is typical upward extension type; namely, add more processors, memory, disk, and network card on a single node. Products from multiple vendors have proved that in conventional commerce load environment, SMP server can provide ability of scaling up ten times of a single processor system. However, as the number of CPU increases, shared memory bandwidth becomes bottlenecks, and multiprocessor competition reduces the utilization of the system bus, so it is difficult to extend to a large scale.
In Shared-Disk structure, each node has its own memory and shared disk. Each node can read and modify all data. Data consistency is ensured through the distributed concurrency control mechanism. As the number of nodes increases, concurrency expenditure increases, so the practical database system built by commercial Shared Disk – usually has only 6-8 nodes.
Shared-Nothing structure belongs to multi-data unit structure of multi processing units. In Shared-Nothing environment, each processor has its own memory and disk storage devices, and all processors are connected through interconnection network among nodes; there is good extensibility for application of less communication and less return results (such as data warehouse and DSS). Thousands of nodes can be achieved.
In DRAC, in addition to using the stand-alone Oracle by unit database, Shared - Disk parallel database can be used, such as Oracle RAC. This is a system blend of the Shared Disk and Shared - Nothing structure system, which can be extended to a larger scale.
Under Shared - Nothing framework, database node will lead to inaccessible data if failure. DRAC provides double writing strategy, and data with high requirements are stored in two nodes. As long as there is a node, the data are still available in a timely manner.
Key technology
DRAC is a complete set of parallel database system; in addition to the above characteristics, in the following are parallel loading, parallel query and data double writing and other key technology.
Parallel loading
The key to improve the loading ability is to improve stand-alone loading ability and make full use of system resources. The parallel loading technology of DRAC includes design at the following levels.
1)Single-threaded direct path load. Loading thread will be noticed to database by data written format by using pretreatment process, and then a large number of records of the client will be accepted, which can write the data into the database by means of direct path load at once, which is the fastest online data loading method provided by Oracle.
2)Stand-alone multithreaded loading at the same time. Every load node maintains a thread, and when a request arrives, a thread is distributed to a database node for loading, which can make full use of bandwidth of load node and computing resources to improve the utilization rate.
3)Parallel load of multi-database. Multiple threads of each load node can make loading for multiple databases at the same time. When there are many load nodes, database load ability can be fully used, which can maximize the loading performance of the system.
Consideration of the above three designs makes DRAC provide very high loading speed and approximate linear load extension ratio.
Data equilibrium is an important problem to be solved by parallel database of Shared - Nothing architecture. The key to solve the data balance is to avoid too many data on one of the nodes; otherwise, the query task on the node will be lead to being the latest; completion time of the parallel task depends on the slowest operation, which may serious cause a decline in query extensibility. DRAC chooses the smallest node for loading to keep balance of the current data. If a database node fails and restarts, which leads to small loading quantity, there will be loading too much in a short period of time. For stream-oriented data applications, DRAC take periodic counting method. When beyond a cycle, the count returns to zero. When the above situation occurs, small quantity of the last cycle data won't affect a cycle of data balance.
Parallel query
In management of streaming data, data table with flow characteristics tend to become very great with growth over time. Mass data table is distributed and stored in different data nodes, which are the basis of DRAC parallel query. As shown, query server is also deployed with a database, used to store intermediate results. Query service break up SQL from the client into local data query on database node and post-processing query of comprehensive subquery. Subqueries process the original data in each database node, and intermediate results of each node is summarized to query nodes to perform post-processing query, which can provide users with the final result.
Parallel query processing based on distribution list and replication table
When the intermediate result set is small, this method has a good scalability. The link operation between the two distribution tables can be realized by using data redistribution between the nodes.
In order to achieve robustness of the query, the query service implements the client timeout and server resources recovery mechanism, ensuring that when there is exception in the client-side, no impact will be caused for the system. In addition, the client can take the initiative to cancel a query.
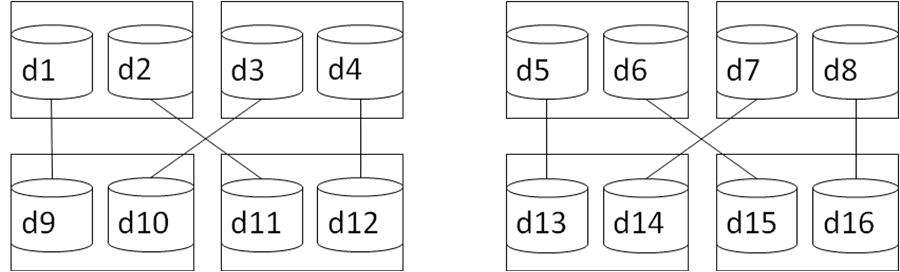
Double writing of data
For users who have high requirements on data reliability and availability, DRAC provides data double writing function. As shown in the figure, two databases will be created on each database node; for instance, d1 and d2 are two databases of the same physical machine. Database among nodes show complete mirror image, and data will be saved in the mirrored databases at the time when the data is written. Interlaced mirror relationship is given in the figure, data can be used in addition to failure of any database data; all above or below database nodes are damaged, and the data in the system is still available.
High availability
DRAC uses a variety of ways to improve the availability of the system, which can provide 7*24 hours of uninterrupted operation. According to distance from a user, DRAC high availability includes the following aspects.
Load balancing mechanism of high availability. Two loading balancers are configured under DRAC standard, and when one of them is unavailable, a client interface library will use another one automatically, so the load balancer is highly available.
Services with high availability: each DRAC service (loading, query, replication engine) can be configured in multiple physical servers; as long as there is one available, this service is available.
Highly available database: DRAC system is configured with multiple independent database nodes. When a database fails, the failure includes temporary failure, node crash and data corruption. If it is a temporary fault or node crash, the ongoing queries cannot obtain result of this part of data, but the rest of the calculation results will be returned to the user on the node and prompt “incomplete result set”. When the node is down, this state continues until the machine restarts. After activating double writing mechanism, even if database fails, the database data is not lost, and readily available.
Expansibility
In DRAC management system, as long as the database nodes are added, the capacity of the system can be increased. At the same time, all the processing capacity of database is similar to for the processing power of the whole system, which can also be extended accordingly. When the system scale increases, the performance of the system, namely, expansibility is an important characteristic of parallel system. Before reaching the writing speed of all databases, DRAC data loading performance and the number of load node tend to near-linear growth. Most of the queries show near-linear results with the increase of the number of database nodes.
According to the actual needs of application, servers used to load and query tasks can be easily added and removed, but the overall processing ability is mainly limited by database node capacity.
All nodes can be carried out without interruption to business situation. Software can achieve online upgrade.
DRAC exceeds 18 database nodes in the deployment of a production system, and the processed data amount is more than 400 TB.
System backup and recovery
Introduction to DRAC high availability shows four aspects about how to ensure continuous availability of foreign services when a part of equipment is in failure. In the case that no data loss occurs, only fault equipment shall be replaced, and rejoin it to the system, which can restore the fault.
In order to prevent serious fault of data loss, DRAC provides backup tool dmbk , which can export required data separately from the database node, which are stored on the medium after compression. When required, it reads the data from the backup medium, and imports the original database after decompression.
Simplification of management
Various DRAC services and database nodes are "logical nodes", which can be deployed in any physical node; therefore, for a particular system structure, it is only necessary to indicate the mapping relationship between "logical node" and "physical node”; overall database deployment including the underlying database can be completed through tools. It can be deployed in the system of any number of machines, including a single node.
DiM is a DRAC deployment, monitoring, and management tool based on B/S mode. Mapping relation between “logical node” and “physical node” through interaction with users, and then according to the mapping relation, scripts are generated executed in different nodes, and then guide the users to complete the deployment step by step. It also can complete verification of system deployment correctness and inspection work of various services.
DRAC regularly collects state of system components (such as database node and service node) and the average resource utilization rate, which will be written to a particular table of the database management; users can use a browser to directly check hardware, database, and services and other monitoring information to get all sorts of statistics. At the same time, DiM provides starting, stopping and other management operations for a variety of services and unit data that make up the system.







 Register /
Register /















